Welk systeem het meest geschikt is voor de klant hangt af van de behoeften, het budget, kennis van de tooling in de markt en binnen het bedrijf. Zo kan het goedkoper zijn om te kiezen voor gloednieuwe software, maar als er weinig kennis van is binnen het bedrijf zullen de opleidingskosten fors toenemen. Onderaan de streep is het dan maar de vraag of je de klant er mee helpt om zich hieraan toe te wijden. Een handige vuistregel als het gaat om Cloud-migratie is om de Cloud-variant van de al bestaande database te pakken. Bijvoorbeeld een migratie van een on-premises MariaDB naar een Azure Database for MariaDB. Deze zullen beter op elkaar aansluiten waardoor de migratie makkelijker verloopt dan wanneer er gekozen wordt voor een compleet nieuw systeem.
Gedeelde verantwoordelijkheid
Naast een inschatting van de beschikbare kennis is het ook belangrijk om in kaart te brengen in welke mate het bedrijf controle wil en kan weggeven. Voor het ene bedrijf is het belangrijk om controle te houden over alle besturingssystemen en databases, terwijl het andere bedrijf juist zo min mogelijk zorgen wil hebben over opslag en zich wil focussen op hun kernprocessen. Microsoft Azure biedt daarom op hoofdlijnen een drietal services aan, namelijk: “Infrastructure-as-a-service” (IaaS), “Platform-as-a-service”(PaaS) en “Software-as-a-service”(SaaS). Bij IaaS heeft Microsoft de minste controle en verantwoordelijkheid en bij SaaS juist de meeste.
Wie waar controle over heeft en dus ook de verantwoordelijkheid over draagt, is te zien in figuur 1, het “gedeeldeverantwoordelijkheidsmodel”. Het is helaas niet mogelijk voor een bedrijf om van de ene op de andere dag over te stappen naar een service die meer controle en verantwoordelijkheid bij Microsoft legt. Bij het verplaatsen van de verantwoordelijkheid hoort namelijk een bepaald niveau van toewijding binnen en inrichting van het bedrijf.
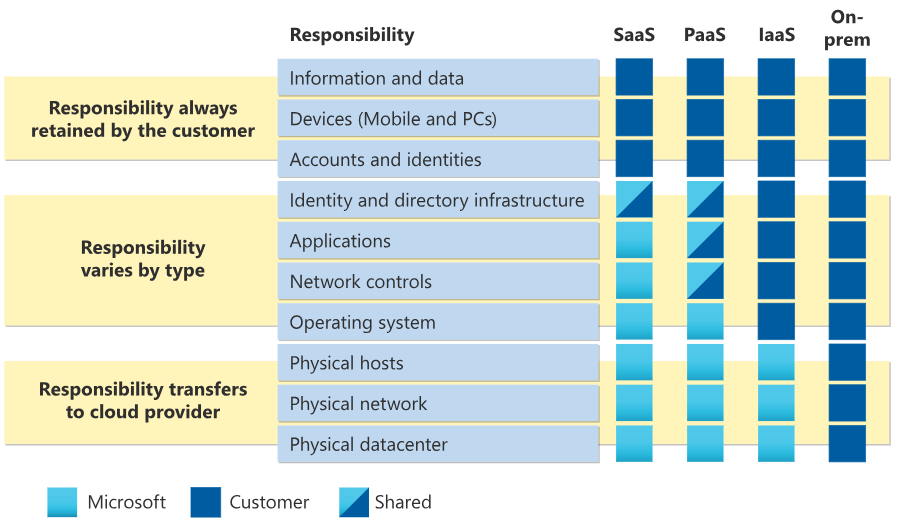
Figuur 1: gedeelde verantwoordelijkheidsmodel van Microsoft (bron)
Architectuur van Cloud-opslag
Nu we de verschillende opslagtypes hebben besproken, zijn we toegekomen aan het inrichten van de Cloud-opslag: de architectuur. Vaak komt het namelijk voor dat er niet één maar meerdere (meestal Software-as-a-Service-) systemen worden gebruikt binnen een bedrijf om alle gegevens op te slaan. Denk hierbij aan een IT-systeem met daarin alle personeelsgegevens en uren, of een IT-systeem waar de magazijnvoorraad in bijgehouden wordt, of een IT-systeem waarin alle financiën worden vastgelegd. Elk IT-systeem kan weer op zijn eigen manier ingericht zijn en gegevens op een andere manier opslaan. Ook bij onze hypothetische klant is dit het geval; de website is maar een klein onderdeel van alle informatie binnen een bedrijf. Gegevens zoals product afbeeldingen hoeven enkel opgeslagen op opgehaald te worden. Uit andere gegevens kunnen we meer inzichten krijgen. Via de website krijgen we gegevens binnen over zowel verkochte producten als klantgegevens. Door de verkochte producten te combineren met bijvoorbeeld de magazijnvoorraad kan er gericht inkopen gedaan, wat voorkomt dat producten uitverkocht raken of te vroeg worden ingekocht. Voordat er inzichten uit de data gehaald kunnen worden, is het nodig om alle benodigde data te clusteren en op te schonen. Het samenbrengen van de data van alle verschillende IT-systemen/applicaties binnen een organisatie kan erg complex zijn. Het is daarom belangrijk om goed over dit proces na te denken voordat het geïmplementeerd wordt.
Over de jaren heen zijn er verschillende data-architecturen ontwikkeld en toegepast in het bedrijfsleven. Het relationele datawarehouse, ontwikkeld in de jaren 80, was één van de eerste grootschalig toegepaste architecturen. Daarna werden de data lake, “modern” data warehouse, data fabric, data mesh en data lakehouse tussen de jaren 2010 en 2020 ontwikkeld, elk met zijn eigen karakteristieken. Ondanks dat elke architectuur zijn eigen voor- en nadelen heeft zien we toch dat tegenwoordig in de meeste gevallen Data lakehouse de “go-to solution” is.
Dit is wellicht een goed moment om te benadrukken dat dit niet betekent dat vrijwel alle bedrijven momenteel met deze architectuur werken. Deze bedrijven werken nog met een architectuur die op het moment van kiezen het beste bij hun bedrijfsstructuur en –inrichting aansloot. Een architectuur verander je namelijk niet van de ene op de andere dag. Maar wanneer er op dit moment voor een nieuwe architectuur gekozen wordt, is dat in de meeste gevallen een data lakehouse. Maar natuurlijk wordt er in specifieke gevallen nog regelmatig gekozen voor één van de andere architectuurvormen.
De redenen waarom data lakehouse steeds populairder wordt, is omdat een data lakehouse eigenlijk een combinatie is van een data lake en een data warehouse, zie figuur 2 . Hierbij wordt er gebruik gemaakt van een overkoepelende laag, namelijk de delta lake wat bijdraagt aan het simplificeren van datamanagement. Hoe een data lakehouse precies in elkaar zit heeft een van onze collega’s, Dennis van Zanten, al besproken in zijn blog “Lakehouse”, kijk hier vooral naar voor een diepteanalyse van een data lakehouse. Daarnaast is in de blog “Schaalbare dataprocessing met Databricks” van Sander op ’t Hof en Sven Relijveld ingegaan op de data lakehouse-architectuur binnen Databricks. Doordat deze twee blogs het concept data lakehouse vergelijkt met andere architectuur vormen zal in deze blog het data lakehouse-concept niet verder toegelicht worden. Wel gaan we verder in op het inrichten van een data lakehouse omdat deze architectuur door steeds meer bedrijven gebruikt wordt.
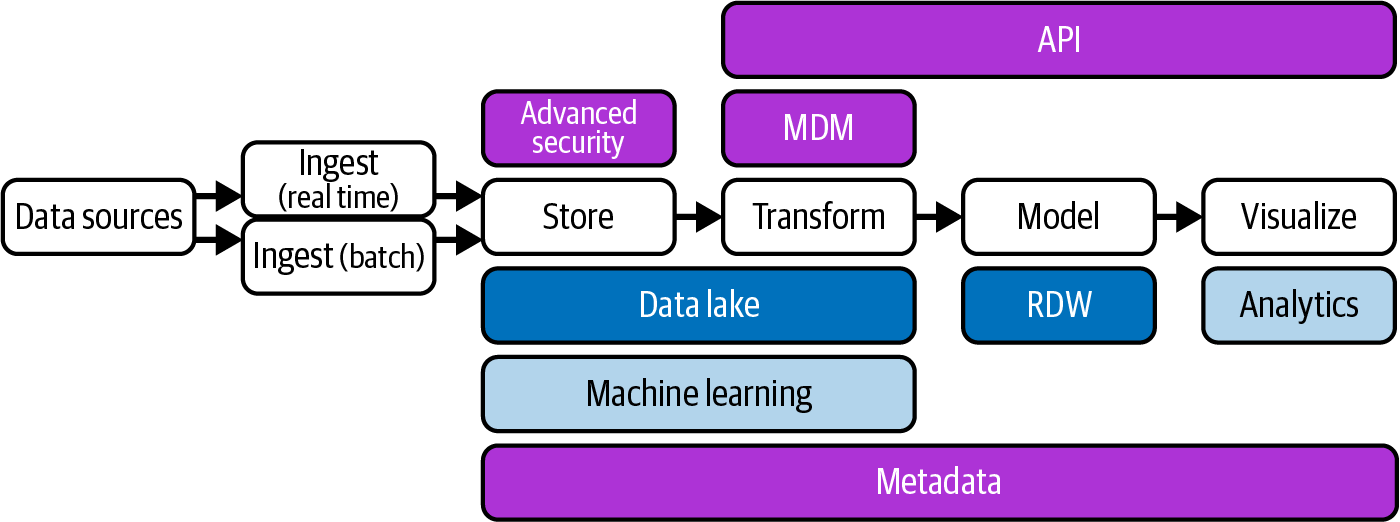
Figuur 2: Data lakehouse (boek: James Serra,
Deciphering Data Architectures)
Brons, zilver en Goud
Om er zeker genoeg van te zijn dat alle data op dezelfde plek is opgeslagen in dezelfde vorm en structuur hanteren veel organisaties het drie lagen principe. Elke laag heeft zijn eigen functie en wordt gebruikt voor het aanduiden van de gereedheid van de data. Over de jaren heen zijn hier veel variaties en benamingen voor geweest. Tegenwoordig is het gangbaar om deze drie lagen de brons-, zilver- en goudlaag te noemen. In de bronslaag komt alle ruwe data binnen vanuit de bronsystemen. Dit is data direct vanuit een bronsysteem. Voor het inrichten van je bronslaag is het belangrijk om alvast goed na te denken over hoe de data opgeslagen en gebruikt dient te worden in de lagen die erna komen. Vaak raden wij de meest flexibele vorm van opslag aan voor de bronslaag. Denk aan een data lake waar al je data eerst kan landen. Dit voorkomt dat data niet opgeslagen wordt en voor altijd verloren gaat. Mocht er een CSV-bestand aangeleverd worden met een verkeerde naam, of onbekende kolommen, wordt deze opgeslagen en bewaard in de bronslaag. Dit in tegenstelling tot directe opslag in een tabel, waar een error verschijnt, en de data niet bewaard wordt. Dit maakt het systeem afhankelijk van de aanleverende partij.
Blog storage is een goed voorbeeld van een opslagmethode die uiterst flexibel is. Het is hierbij wel belangrijk om in de bronslaag al goed na te denken over de directorystructuur. Naast dat het belangrijk is in welke structuur de data opgeslagen gaat worden is het ook nodig om te bepalen hoe vaak de data in de toekomst opgevraagd gaat worden. Hierop zal de juiste access tier van een storage account gekozen worden. Als de data direct opvraagbaar moet zijn dan is een “hot” access tier een goede overweging. Wanneer de data puur voor archivering opgeslagen dient te worden kan er beter gekozen worden voor de “archive” access tier. Bij de “archive” access tier liggen de kosten voor het opslaan van de data lager dan bij een hot access tier. Ook is er een verschil in de beschikbaarheid van de data. Bij een Hot access tier heb je direct toegang tot de data, terwijl bij de “archive” access tier het enkele uren kan duren. De kosten liggen dan lager, maar het opvragen van de data kan enkele uren duren.
In de zilverlaag wordt de data uit de bronslaag gehaald en bewerkt om de data in de juiste format en stijl te krijgen om te voldoen aan de eisen van de organisatie. Hoe de data bewerkt wordt kan op verschillende manieren worden gedaan. Zo kan ervoor gekozen worden om alle transformaties in één keer te verwerken. Dit wordt ook wel de “stored procedure” stijl genoemd. Een andere optie is om alle transformaties in kleinere stappen op te breken. Hierbij kan ervoor gekozen worden om de data tussentijds op te slaan in een tijdelijke tabel of view. Beide methoden worden veel gebruikt. Welke van deze methodes gebruikt wordt is afhankelijk van de hoeveelheid transformaties, de duur van alle transformaties bij elkaar, hoe vaak er een wijziging aangebracht dient te worden in de code die voor de transformatie zorgt, en hoe vaak de desbetreffende data moet worden gewijzigd. Als deze data wijzigt zal de transformatie ook vaak mee wijzigen. De opslag in de zilverlaag gebeurt in tabellen of Parquet files in de datalake. Belangrijk is dat de data in de zilverlaag zo generiek mogelijk is zodat meerdere afdelingen binnen een organisatie hier gebruik van kunnen maken.
Nadat de data bewerkt is in de zilverlaag wordt het overgezet naar de goudlaag waarna het uiteindelijk wordt gebruikt om de informatie uit de data te kunnen halen. In deze laag worden weinig tot geen veranderingen meer gedaan aan de data. Alleen als het nodig is kan de data hier nog conversies ondergaan bijvoorbeeld om de data op een andere manier geaggregeerd te krijgen voor een specifieke afdeling. Vaak is de goudlaag dimensioneel gemodelleerd omdat dit de meest makkelijke en gebruikte manier is waarop de visualitie tool overweg kan met de data.
Hoe richt je een tabel in?
Tot slot willen we nog een handige tip meegeven die gebruikt kan worden voor het inrichten van je tabellen binnen je opgezette architectuur. Net zoals dat het belangrijk is om goed na te denken over de architectuur van je dataopslag, geldt dit ook voor het inrichten van je tabellen. Vaak zien wij bij klanten dat er niet altijd even goed is nagedacht over de opzet van een tabel. Zo kon bij het aanmaken van de tabel niet het nodig zijn om data over tijd op te slaan, maar na verloop van tijd toch wel nodig blijkt te zijn. Dit kan voor veel extra werk opleveren en wil je natuurlijk altijd zo veel mogelijk voorkomen.
Om ervoor te zorgen dat de data correct wordt opgeslagen over tijd is het verstandig om aandacht te besteden aan de datalaadstrategie. De datalaadstrategie bepaalt of de bestaande data volledig wordt verwijderd en weer opnieuw ingeladen of dat alleen de nieuwe data wordt toegevoegd en bestaande data wordt verwijderd of geüpdatet.
Als de data volledig wordt verwijderd en opnieuw wordt doorgeladen wordt er dus geen historie van de data bijgehouden, je verwijdert immers alles. Deze methode is het meest simpel en minst tijd efficiënt mits het niet grote hoeveelheden data gaat. Wanneer er voor de tweede optie gekozen wordt, het toevoegen van nieuwe en updaten of verwijderen van bestaande data, dan is het ook belangrijk om de historie van de data bij te houden. Doe je dit niet dan kan dat zorgen voor dubbele data en dit wil je natuurlijk.
Om goed bij te houden welke regel voor de juiste tijdsperiode geldt, kan het concept van “slowly changing dimensions” (SCD) gebruikt worden. SCD is een concept dat wordt gebruikt in datawarehousing en data-analyse om te beschrijven hoe dimensiegegevens (zoals producten, klanten, locaties, enz.) veranderen in de loop van de tijd en hoe deze veranderingen worden beheerd en vastgelegd. In totaal zijn er 6 varianten binnen het SCD-concept, maar binnen OneDNA wordt met name gebruikt, omdat deze alle componenten van variant 1 tot en met 5 samenvoegt en dus het meest complete beeld geeft. In tabel 5 is een voorbeeld van een tabel dat ingericht is volgens SCD type 6.

Tabel 5: voorbeeld van tabel dat ingericht is volgens SCD type 6 (bron)
Ons op maat gemaakte advies voor ons kleine fictieve e-commercebedrijf omvat het gebruik van een Azure SQL Database voor het beheer van klantgegevens, Azure Table Storage voor het opslaan van gebruikerssessies en Azure Blob Storage voor het hosten van websiteafbeeldingen. Deze PaaS-oplossingen bieden flexibiliteit, schaalbaarheid en verminderen de operationele complexiteit, waardoor het bedrijf zich kan concentreren op groei en innovatie. Door dit te combineren met industriestandaards zoals medaille-opslag en slowly changing dimensions, bieden we de klant een robuuste basis voor het beheren en analyseren van hun gegevens.
Dit was het voor deze eerste deel van de blog “Wat zijn de mogelijkheden in Cloud-opslag”. In deel twee gaan we het hebben over het beveiligen van je Cloud-opslag. Mocht je nou graag meer willen weten en echt niet kunnen wachten tot de volgende blog of ben je gewoon nieuwgierig wat wij, OneDNA, allemaal doen? Neem dan even contact op via onze contact gegevens op de website.