DataOps: Breng DevOps naar je dataplatform in de cloud
Data-gedreven werken, de heilige graal voor menig organisatie. We zien dat een steeds grotere en meer diverse groep aan bedrijven en organisaties hun strategische keuzes mede of volledig laten bepalen door het gebruik van data. Tegelijkertijd zien we in het veranderende landschap van (cloud) data, dat het vermogen om data efficiënt en effectief te beheren een uitdaging blijft.
In het verleden vertrouwden data- en BI-afdelingen vaak op opzichzelfstaande processen, programma’s en teams, vaak met een on-premise data warehouse, waarin data werd gecentraliseerd en daarvanuit werd gerapporteerd. De isolatie van de mensen en processen leidde tot trage ontwikkelingscycli en het belemmerde de samenwerking tussen Business users, BI-specialisten, Data Engineers en Data Scientists. Organisaties worstelen met steeds grotere hoeveelheden data die wordt gegenereerd in de diverse systemen en dataspecialisten merken dat sommige traditionele benaderingen van verwerking niet altijd toereikend zijn. Data-gedreven werken komt in de knel doordat er niet vanuit een integrale bril wordt gekeken naar teams die met data werken.
Door de shift naar de cloud is er ook een verschuiving ontstaan in de manier waarop data wordt uitgewisseld. Daarnaast komen de werkzaamheden van de data engineers steeds dichter te liggen bij die van software engineers en wordt er verwacht dat de dataspecialisten meer en meer verantwoordelijk zijn voor hun eigen infrastructuur. De verschillende onderdelen van infrastructuur worden meer en meer benaderd als software-componenten en het is een uitdaging op zichzelf om die onderdelen, ieder met een eigen software development lifecycle, te operationaliseren.
Hier komt DataOps om de hoek kijken. Dit is een methodologie die inspiratie put uit DevOps-principes en -praktijken van de Software Engineering. Daarmee verandert de kijk op het systeem en de werkwijze waarop data wordt verwerkt, behandeld en geleverd vanuit het Data Platform van een organisatie. DevOps, dat in de wereld van softwareontwikkeling al een grote impact heeft gehad, introduceerde continue integratie, continue delivery en automatisering om de ontwikkeling te stroomlijnen. DataOps breidt deze principes uit naar de wereld van data, waarbij een samenwerkende, iteratieve en geautomatiseerde aanpak van dataengineering en -analyse wordt geïntroduceerd.
Door DataOps-principes te omarmen binnen het Cloud Data Platform kunnen organisaties een reeks voordelen verkrijgen, waaronder verbeterde data-agility, kortere doorlooptijd tot nieuwe inzichten, doorlopende controle van datakwaliteit, verbeterde samenwerking tussen verschillende functies en een efficiëntere benutting van middelen.
In deze blog licht ik een aantal belangrijke aspecten van DataOps-implementatie toe, zoals versiebeheer, geautomatiseerde tests, continue integratie en implementatie van datapipelines, monitoring en observatie en de integratie van beveiligings- en compliance-maatregelen. Bovendien beschrijf ik hoe DataOps een cultuur van datasamenwerking bevordert, waar Data Engineers en Data Scientists en BI-specialisten naadloos kunnen samenwerken met business users om waardevolle inzichten te verkrijgen en datagedreven besluitvormingsprocessen te stimuleren.
DevOps vs DataOps
Het DevOps gedachtegoed ontstond als een brugfunctie tussen ontwikkelaars en systeembeheerders, om de ontwikkeling en releases van code te optimaliseren met minimale impact op bestaande systemen. DevOps was een manier om multidisciplinair samen te werken en alle onderdelen rondom dit proces te automatiseren en te monitoren. DataOps is een afgeleide filosofie, die zich focust op het beheren van robuuste data- en informatievoorziening.
Tussen DevOps en DataOps bestaat overlap, maar er zijn ook nuanceverschillen. Versiebeheer, automatisering, continue testen, Continue-Integratie en Continue Delivery (CI/CD-pipelines) en meebewegende infrastructuur spelen in beide disciplines een grote rol. Over dit laatste onderwerp Infrastructure-as-code (IaC) heeft mijn collega Sander een uitgebreide blog geschreven.
Tegenover die overeenkomsten staat een belangrijk verschil, dat software na de release een statisch product is, met een relatief onveranderlijke set aan inputs en data als één van de outputs. Data pipelines worden ontworpen om een grote hoeveelheid data te verplaatsen, waarbij data zowel een input als een output is en de set aan inputs van nature aan verandering onderhevig is. Het doel van een software-product is om voor een gebruiker een doel of taak te vereenvoudigen, terwijl een data-pipeline de gebruiker van informatie wil voorzien. Dit verschil leidt ertoe dat een softwareproduct wordt ontworpen om stabiel te zijn, terwijl een data pipeline meer nadruk legt op robuust zijn tegen veranderende omstandigheden.
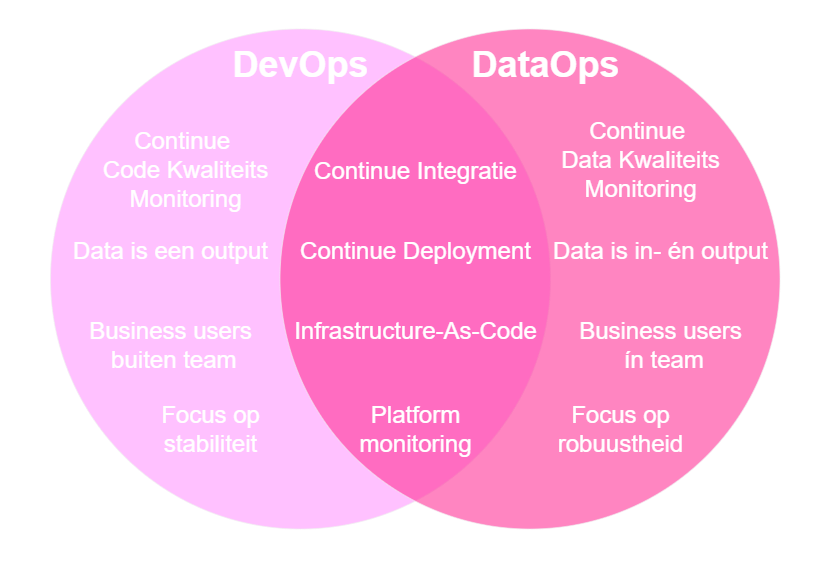
Figuur 1: Overlap tussen DataOps en DevOps
Deze nuance-verschillen komen tot uiting in zaken waar de nadruk op komt te liggen. In DevOps ligt de nadruk op functionele software, terwijl in DataOps, de nadruk ligt op bruikbare informatie.
Data legt binnen analytische systemen in de cloud vaak een langere weg af dan in de on-premise systemen, van de originele bron tot het eindproduct, zoals een rapportage of een machine-learning model. Het pad wat de data volgt heeft dan ook meer de vorm van een supply chain dan een enkel systeem, met alle complexiteit die daarmee gepaard gaat. In het klassieke ETL-framework werd data vanuit de bron ontsloten, gelijk getransformeerd tot een bruikbaar product en vervolgens geladen naar een plek waar het kon worden gebruikt. Vaak vonden deze stappen plaats in één of een klein aantal on-premise software-systemen, waarin het datawarehouse centraal stond, die garant stond voor de code voor transformaties, de rekenkracht en de opslag van de data.
In de cloud kunnen deze componenten makkelijker van elkaar gescheiden worden gebruikt en geschaald, waarmee de componenten kunnen specialiseren in één van de stappen in dit proces. Deze trend komt samen in de ‘Moderne Data Stack’, die bestaat uit een aantal loosely coupled cloud componenten, die via RESTful API’s in verbinding staan met elkaar. In sommige producten, zoals het Lakehouse of Microsoft Fabric worden dan onderdelen van de data supply chain weer samengevoegd voor verbeterde integratie en gebruikerservaring, waarbij individuele delen nog steeds schaalbaar zijn. Verder wordt er vaker gekozen voor een ELT-design, mede door de veel goedkopere opties voor opslag en de mogelijkheid om schema-less, oftewel, zonder vooraf gedefinieerde tabelstructuur data te ontsluiten. Hierin wordt data eerst in zijn geheel ‘as is’ naar een landing zone in een object store zoals Azure Data Lake Storage wordt gekopieerd en vervolgens apart getransformeerd.
Vanwege de modulariteit en specialisatie van (cloud) softwarecomponenten, komt er meer nadruk te liggen op integraties tussen de onderdelen, die bovendien in een eigen software development lifecycle kunnen zitten. Beslissingen die in het begin van het adoptieproces worden genomen, zijn lastig om later te herzien, dus dienen weloverwogen te worden genomen.
Data Platform & DataOps
Aan de hand van een voorbeeld design van een end-to-end dataplatform licht ik verscheidene componenten in de DataOps filosofie toe. Het dataplatform wat we bekijken is een voorbeeld, gebaseerd op een real-life case van OneDNA.
Figuur 2: Data Platform design voor Lamda-architectuur. Deze afbeelding is interactief. Op een laptop of monitor komt dit het beste tot zijn recht
Het platform bestaat uit meerdere cloud-componenten: De ontsluitingen van REST API’s en Externe databasesystemen worden gedaan met horizontaal schaalbare Azure Functions, waarin asynchroon data kan worden gekopieerd naar een landing zone. Events uit message-systemen zoals Service Bus worden geregistreerd via een Event Grid, die een Function aanstuurt om de message naar een Azure Event Hub voor verwerking te sturen. Met deze routes kunnen zowel batch- als streaming data kunnen worden ontsloten, waarbij er de Streaming route via de Event Hub loopt voor het verwerken van events uit message-systemen en een batch-route die wordt aangestuurd door Azure Data Factory. Een Databricks omgeving met een medaillon architectuur zorgt voor de data verwerking en distributie richting (ML-)applicaties in Azure Machine Learning en rapportagesystemen in Power BI. Het geheel past binnen de kosten-, security en compliance-vereisten vanuit het Cloud Adoption en Well-architected framework van Azure, met geïntegreerde Cost management, Identity & Access Management, Azure Policies, een DevOps omgeving voor de ontwikkeling en Purview voor de Data Governance.
1. Versiebeheer
Versiebeheer is een essentieel onderdeel van elke softwareontwikkeling en Git is een van de meest populaire systemen voor versiebeheer. Ook voor ontwikkelaars aan een dataplatform biedt versiebeheer de mogelijkheid om wijzigingen in hun code op een georganiseerde en traceerbare manier te beheren. Azure DevOps Repos biedt ontwikkelaars een omgeving voor Git-versiebeheer, waarmee teams efficiënt samenwerken aan projecten en wijzigingen in de code transparant kunnen beheren. Met functies zoals branchebeheer, pull-requests en integratie met CI/CD-pipelines stroomlijnt het platform de ontwikkelingsworkflow, waarbij elke codeaanpassing wordt vastgelegd en gedocumenteerd voor traceerbaarheid en herstelbaarheid. Dit bevordert efficiëntie, codekwaliteit en samenwerking. In een goed versiebeheerd dataplatform, waar makkelijk oudere versies van het platform en de data zijn terug te halen, zijn álle componenten opgenomen in je versiebeheer-tool. Naast je reguliere code en je infrastructuur-wijzigingen, die als Infrastructure-as-Code in Bicep of Terraform kunnen worden beheerd, kunnen ook designs en architectuurplaten kunnen worden opgenomen in versiebeheer binnen de coderepositories. Door Designs-as-Code te gebruiken en het eveneens onder het centrale versiebeheersysteem op te nemen, blijven designkeuzes aansluiten op de veranderende systemen. Wanneer je start moet je de keuze maken wat de scope is van de verschillende componenten en hoe je de lifecycle wil beheren. Ga je vanuit een enkele repository het gehele platform in één keer deployen of zet je meerdere repositories onder één project? Wellicht kies je ervoor om meerdere projecten in je DevOps tenant onder te brengen, met eigen toegangsbeheer, wiki’s en richtlijnen.
Eén geijkte strategie die je kan aanhouden is om de verschillende componenten met eigen ontwikkel lifecycles onder te brengen in een eigen project, waarbij er één dedicated project wordt opgezet en onderhouden door gecentraliseerde templates. Deze strategie is goed uitbreidbaar naar andere applicaties die in je organisatie worden ontwikkeld, die fungeren als bron of doelsysteem van de data in je platform.
![]()
Figuur 3: Gecentraliseerde project voor templates in Azure DevOps met gedecentraliseerde projecten voor applicaties of cloudcomponenten.
1. Geautomatiseerde tests
Anders dan in DevOps, bestaan geautomatiseerde testen voor je dataplatform niet alleen uit testen voor functionaliteit, maar ook uit testen voor datakwaliteit, wat specifiek is voor DataOps. Functionaliteitstesten worden gedaan op de software-componenten en valideren of de code doet wat het moet doen. Wanneer je bijvoorbeeld ontsluitingen schrijft in Python, gehost in Azure Functions, dan kan je het Pytest framework gebruiken om te valideren of al je functies de juiste uitkomst hebben. Wanneer je deze stap integreert met je CI-pipeline, kan je de uitkomsten van je testsuite gebruiken om een pull-request wel of niet te accepteren. Ook voor orkestratie applicaties als Azure Data Factory, zijn er test-mogelijkheden, maar deze frameworks kunnen lastiger op te zetten zijn, omdat ze de visuele Data Factory benadering loslaten en C# vereisen.
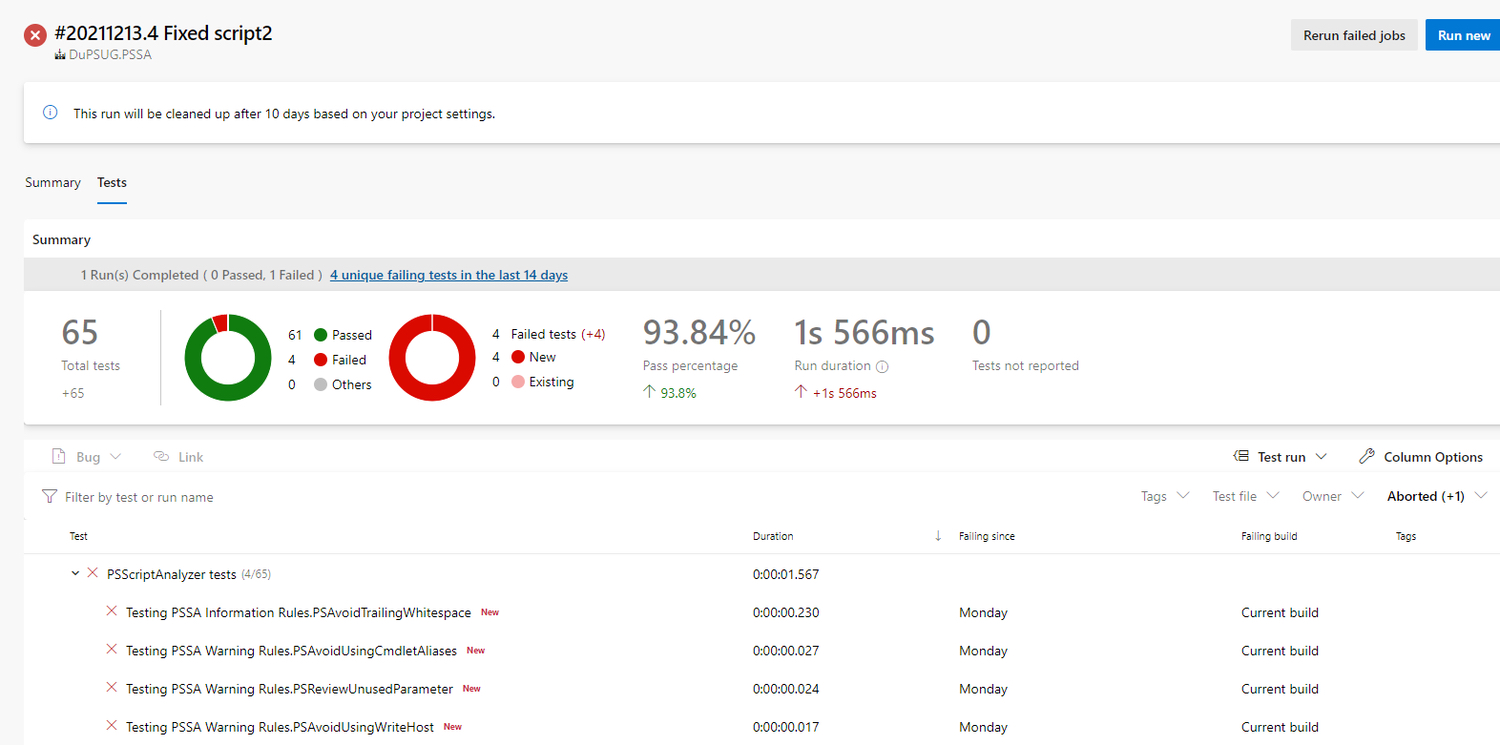
Figuur 4: Functionaliteitstests in pytest, gegenereerd als rapport in Azure Pipelines
Hiernaast bestaat het geautomatiseerd testen voor datakwaliteit, met behulp van frameworks zoals dbt tests, Elementary, Great Expectations, Monte Carlo of Synq. In deze frameworks definieer je de guardrails waaraan je datasets dienen te voldoen, die je vormgeeft als SQL queries. Deze queries dienen een succesvolle of onsuccesvolle uitkomst te hebben, vergelijkbaar met de unit-tests. Echter deze data-tests worden niet enkel bij integratie gedraaid, maar op continue basis uitgevoerd en er wordt doorlopend over gerapporteerd. Deze aanpak maakt het mogelijk om op efficiënte wijze data-integriteit en consistentie te waarborgen door deze automatische controles op ontbrekende waarden, inconsistenties en andere datafouten uit te laten voeren. Deze zaken continue monitoren kan een belangrijk onderdeel vormen in de strategie om de kwaliteit van datasets te waarborgen, zeker als deze aan veranderingen onderhevig zijn. Dit verhoogt de betrouwbaarheid van de data en versterkt de basis voor datagedreven besluitvorming in de organisatie.
Figuur 5: Elementary als framework voor continue testen van datakwaliteit. Deze afbeelding is interactief. Op een laptop of monitor komt dit het beste tot zijn recht
3. Continue integratie & continue delivery
Continue integratie is een onmisbaar aspect van moderne softwareontwikkeling, zowel vanuit een security- als een kwaliteitsinvalshoek. Het gebruik van code-kwaliteitscheckers zoals CodeQL of SonarCube en pre-commit hooks met linters zoals SQLfluff voor SQL en Black voor Python draagt aanzienlijk bij aan het verbeteren van de codekwaliteit. CodeQL maakt het mogelijk om automatisch kwetsbaarheden en fouten in de code op te sporen, waardoor ontwikkelaars potentiële problemen vroegtijdig kunnen identificeren en oplossen. Aanvullend bieden pre-commit hooks met linters voor SQL, YAML en Python consistente en gestandaardiseerde codeformaten, waardoor de leesbaarheid en onderhoudsvriendelijkheid van de code verbeteren. Je kan pre-commit lokaal uitvoeren, nog vóór je naar de remote branch commit. Maar je kan het ook als achtervang gebruiken om te garanderen dat alle pull-requests van je ontwikkelaars featurebranches naar je gezamenlijke branch, aan dezelfde standaarden voldoen. Voordelen van eerst pre-commit lokaal uitvoeren, is dat er minder build minuten worden gebruikt en dat je kan voorkomen dat er foutief credentials worden meegestuurd. En een combinatie is natuurlijk ook goed werkbaar.

Figuur 6: Precommit als lokale uitvoerder, vóór de commit naar de remote repository. Het valideert code-standaarden en voorkomt dat kwalitatief onvoldoende code in gebruik wordt genomen.
Voor de delivery van de data pipelines, wordt niet enkel gekeken naar de kwaliteit van de code tijdens de integratiefase. Ook kan je kijken naar load-tests door middel van JMeter in je integratie-pipeline om de grenzen op te zoeken van de verwerking van je API-requests. Specifiek in event-driven of streaming data-pipelines is dit een must, om de grenzen van het volume van je verwerking te meten. Voor de cloudcomponent waar de transformaties worden gedaan, is het van meerwaarde om documentatie te genereren, in plaats van handmatig bij te werken in een tekstdocument. Deze vorm van Documentation-as-Code bestaat uit dynamische template-files die tijdens de build-fase van de pipeline worden gevuld, waardoor er wordt afgedwongen dat informatie over het ontwikkelproces wordt opgeleverd. Voorbeelden zijn geautomatiseerde release-notes voor dataproducten, die stellen welke features er zijn opgeleverd met een link naar de pull request, geautomatiseerde generatie van lineage graphs in bijvoorbeeld Microsoft Purview of dbt docs.
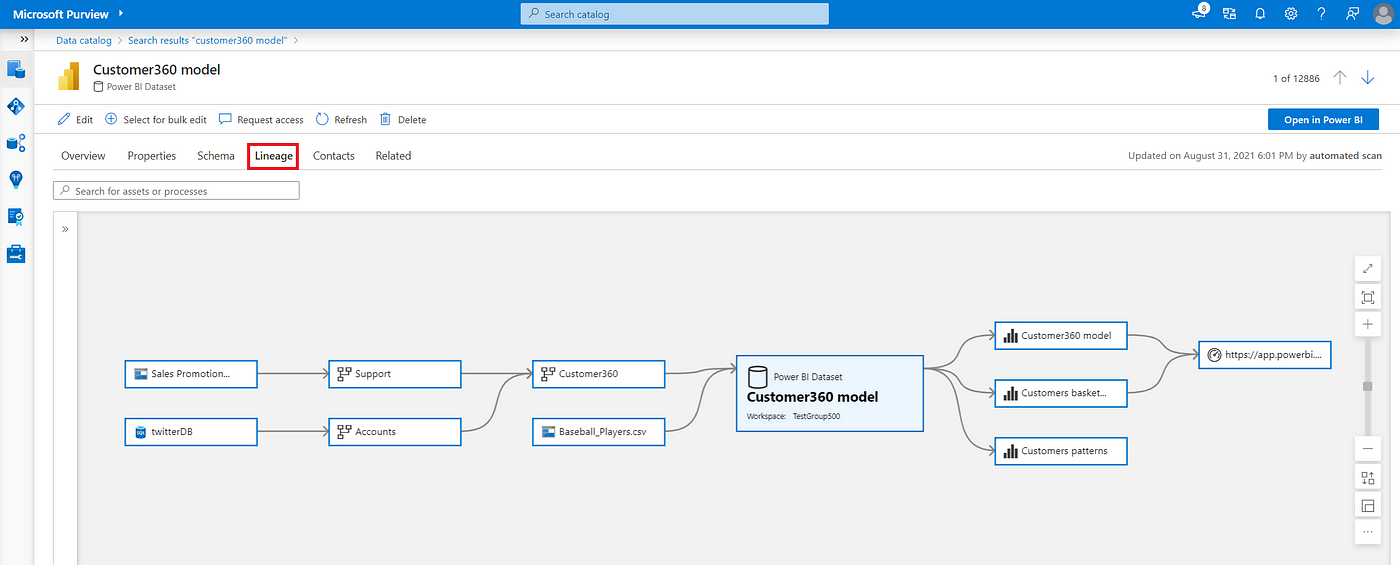
Figuur 7: Azure Purview Lineage graph, waarin de verwerking van de data wordt gevisualiseerd van bron tot aan eindproduct.
Ook de datamodellen in de vorm van ERD’s kunnen worden gegenereerd met bijvoorbeeld dbt-erd en ter beschikking gesteld daarvan met dbdocs. Je zou, als je het wat grootschaliger wil aanpakken en het budget ervoor hebt, ook kunnen opteren voor een git-integrated interactieve database design tool als SQLDBM.