Schaalbare data processing met Databricks: Hoe zet je het goed in?
In de markt zien we dat verschillende tools gebruikt worden voor dataverwerking. Dit was vroeger al het geval en het aantal tools is in de loop van tijd alleen maar groter geworden. Wat is er nu wel veranderd in de afgelopen jaren? Dat zijn de gebruikers van de data. Steeds meer gebruikers willen bijvoorbeeld toegang tot ruwe data om te analyseren of analytische modellen op te maken. De inzichten die verkregen worden door rapportages, zijn niet voldoende om de bedrijfsvragen te beantwoorden of ze duren langer dan waar de organisatie op kan wachten. Een analytisch platform bied de oplossing om dit te kunnen verhelpen. In deze blog gaan we inzoomen op (Azure) Databricks, een platform dat OneDNA in de afgelopen jaren in toenemende mate succesvol heeft geïmplementeerd voor haar klanten. Met deze ervaring op zak delen wij de ins en outs van Databricks, wat is het en wat kan je ermee?
Databricks Lakehouse architectuur
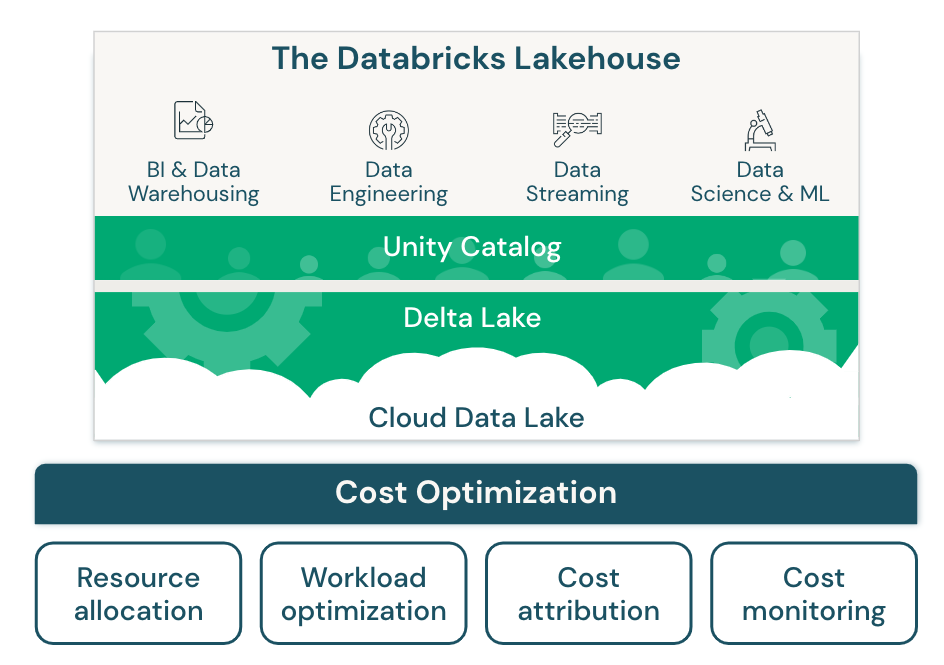 Databricks is grondlegger van de Lakehouse architectuur, een hybride vorm van dataverwerking, die de voordelen van datawarehouses en data lakes in één platform combineert. Door die combinatie kunnen gebruikers profiteren van de schaalbaarheid en kosteneffectiviteit van een data lake en de rekenprestaties/data kwaliteit van (cloud) data warehouses. De opslag van data wordt binnen het platform gedaan in Delta, een open source bestandsformaat dat is gebaseerd op Apache Parquet. Dit is een opslagindeling met kolommen wat zeer efficiënt is voor het opslaan en doorzoeken van grote hoeveelheden data. Hierdoor is het uitermate geschikt voor analytische processen. Delta is beschikbaar in Databricks-runtimes en is het standaard tabelformaat vanaf runtimes 8.0.1. Delta-formaat is opgebouwd uit verschillende componenten, zoals Parquet-bestanden, georganiseerd (of niet) als partities, JSON-bestanden als transactielogboek en een hulpbestand. Delta-formaat is ontworpen om te werken met grote hoeveelheden gegevens en ondersteund ACID transacties. Daarnaast biedt het ook cache functionaliteiten zoals “Delta Cache” en “Result Cache”.
Databricks is grondlegger van de Lakehouse architectuur, een hybride vorm van dataverwerking, die de voordelen van datawarehouses en data lakes in één platform combineert. Door die combinatie kunnen gebruikers profiteren van de schaalbaarheid en kosteneffectiviteit van een data lake en de rekenprestaties/data kwaliteit van (cloud) data warehouses. De opslag van data wordt binnen het platform gedaan in Delta, een open source bestandsformaat dat is gebaseerd op Apache Parquet. Dit is een opslagindeling met kolommen wat zeer efficiënt is voor het opslaan en doorzoeken van grote hoeveelheden data. Hierdoor is het uitermate geschikt voor analytische processen. Delta is beschikbaar in Databricks-runtimes en is het standaard tabelformaat vanaf runtimes 8.0.1. Delta-formaat is opgebouwd uit verschillende componenten, zoals Parquet-bestanden, georganiseerd (of niet) als partities, JSON-bestanden als transactielogboek en een hulpbestand. Delta-formaat is ontworpen om te werken met grote hoeveelheden gegevens en ondersteund ACID transacties. Daarnaast biedt het ook cache functionaliteiten zoals “Delta Cache” en “Result Cache”.
Databricks heeft een eersteklas integratie met Azure, het cloudplatform van Microsoft. Azure biedt een veilige, flexibele en kosteneffectieve infrastructuur voor het hosten van Databricks en het integreren met andere Azure-diensten. Gebruikers kunnen eenvoudig Databricks-clusters opzetten en beheren via de Azure-portal, en profiteren van de native integratie met Azure Data Lake Storage, Azure Synapse Analytics, Azure Machine Learning, Azure DevOps en meer. Door Databricks op Azure te gebruiken, kunnen gebruikers hun data lakehouse bouwen en optimaliseren met minimale inspanning en maximale efficiëntie.
Wat Databricks biedt, is een geïntegreerde en op samenwerking gerichte omgeving voor data-engineers, data scientists en analisten om samen te werken aan hun (big) data-projecten. Zo kan je interactieve notebooks gebruiken, waarmee gebruikers code kunnen schrijven en uitvoeren in verschillende talen (bijv. Python, Scala, SQL) voor gegevensanalyse en modellering, en kunnen voor productie-waardige software producten, packages worden geschreven. Gebruikers, zowel diep technisch als analytisch, kunnen de resources die zij gebruiken eenvoudig opschalen of afschalen op basis van behoefte. Hier is Databricks er als eerste in geslaagd om dit geïntegreerd voor elkaar te krijgen, de concurrentie is bezig aan een inhaalslag op dit moment!
Databricks brengt al deze functionaliteit samen met functies voor beveiliging, toegangscontrole , naleving van regelgeving en is geschikt voor integratie met verschillende bronnen, waaronder data lakes en datawarehouses. Naast Azure, is het ook beschikbaar als beheerde service op belangrijke cloudplatforms zoals Amazon Web Services (AWS) en Google Cloud Platform (GCP).
Over het algemeen vereenvoudigt Databricks het proces van werken met (big) data en geavanceerde analyse, waardoor het een populaire keuze is voor organisaties die de kracht van hun gegevens in de cloud willen benutten. Om Databricks optimaal te kunnen gebruiken moet je in je implementatie over de volgende onderdelen nadenken.
Private compute met vnet-injection
Wanneer we een nieuw platform uitrollen bij een klant zijn er een aantal onderdelen die in het eerste gesprek naar voren komen. Hoe er veilig verbinding gemaakt kan worden met de bronsystemen. Daarnaast willen we voorkomen dat de data van buiten kan worden benaderd. De kans hierop kan verminderd worden door de compute resources van Databricks te plaatsen binnen een virtueel netwerk. Deze VNet-injectie is een functie die beschikbaar is in Azure Databricks. Hiermee worden de Azure Databricks-compute-middelen afgeschermd van het internet en dit geeft verschillende beveiligingsvoordelen. Zoals bijvoorbeeld het verbinden van Azure Databricks met andere Azure-services in een veiligere omgeving, het verbinden van on-premises gegevensbronnen met Azure Databricks en het configureren van aangepaste DNS. Met Vnet-injectie wordt dus het netwerkverkeer tussen Azure Databricks en andere services beperkt tot de services die zijn toegestaan in het Vnet.
Governance met Unity Catalog
In data platforms zien we vaak een risico in het dagelijks beheer, dat gebruikers niet of niet goed kunnen vinden wat voor data er beschikbaar is er en wie er welke rechten toe heeft: Data Governance. Databricks heeft hiervoor Unity Catalog geïntroduceerd, een functie die het mogelijk maakt om gegevens en AI objecten te beheren en te ontdekken in een gestandaardiseerde en gecentraliseerde manier. Met Unity Catalog kunt u metadata, schema’s, toegangsrechten en tags van uw gegevensobjecten bekijken en bewerken, ongeacht waar ze zijn opgeslagen. Unity Catalog integreert met de Databricks SQL Analytics service, waardoor u SQL queries kunt uitvoeren met behulp van een interactieve interface. Unity Catalog biedt ook een API voor programmatische toegang de gegevens en AI objecten, zodat deze geintegreerd kunnen worden met andere applicaties of processen. Unity Catalog helpt om meer waarde te halen uit data door het vereenvoudigen van het beheer, de ontdekking en de analyse ervan.
Identity Management & Access: Veilig bij je eigen data kunnen
Azure heeft een groot identiy ecosysteem waarin gebruikers, automatiseringsaccounts (service principles) en groepen worden aangemaakt en beheert. Vaak is dit op een bepaalde manier gekoppeld aan de HR-afdeling van een bedrijf, waarbij functieprofielen zijn gekoppeld aan specifieke rechten die personen of groepen kunnen hebben. Binnen Azure Databricks kunnen deze gebruikers en groepen worden gesynchroniseerd, waarbij er gebruik wordt gemaakt van Microsoft Entra ID (voorheen Azure Active Directory) om SCIM-provisioning in te stellen. Met SCIM-provisioning kunt u gebruikers, service-principals en groepen syncen naar uw Azure Databricks-account en workspace. Deze integratie kan alleen ingesteld worden middels de Cloud Application Administrator-rol binnen Microsoft Entra ID in combinatie met een Premium-abonnement. De toewijzing kan op twee niveaus worden gedaan, op het accountniveau en op het workspacesniveau. Databricks raadt aan om gebruikers, service-principals en groepen op het accountniveau te synchroniseren en de toewijzing van gebruikers en groepen aan workspaces binnen Azure Databricks te beheren. De workspaces moeten “identification federation” toestaan om de toewijzing van gebruikers aan workspaces te beheren. Als er workspaces zijn die deze functie niet aan hebben staan, moeten gebruikers, service-principals en groepen rechtstreeks aan die workspaces worden toegewezen zonder SCIM-provisioning.
Verschillende laadstrategieën
Het laden van data kan op veel verschillende manieren. Bij het inladen van de data is de bron bepalend hoe de data binnengehaald kan worden. Is de data eenmaal beschikbaar binnen Azure dan beginnen de transformaties. Met die transformatie ontstaat de toegevoegde waarde die belangrijk is voor de business. Dit proces van data inladen wordt ETL genoemd en hier gaan we nog verder op in.
Ophalen van data (Extract)
De eerste stap is het proces om de data op te halen vanuit de bron. Een bron kan een bedrijfssyteem, api, sensor data echt van alles zijn. De structuur kan per bron verschillen en hiermee veranderd ook de manier van het kunnen extraheren van de data.
- Gedeeltelijke extractie: indien de bron een notificatie geeft wanneer een bepaald record is veranderd/aangemaakt. Dit is de makkelijkste manier maar komt niet vaak voor.
- Gedeeltelijke extractie zonder notificatie: Indien een systeem een wijzigingsdatum heeft opgenomen dan kan dit worden gebruikt om de laatste gewijzigde records op te halen. Zo hoeven niet alle records vergeleken te worden op wijzigingen
- Volledige extractie: In dit geval kan het systeem niet aangeven wat de gewijzigde records zijn. In dit geval worden alle records opgehaald om te vergelijken met de voorgaande verlading.
Transformeren van data (Transform)
Nu de data ontsloten is kan de volgende stap het transformeren beginnen. Met het transformeren wordt de ontsloten data veranderd om bijvoorbeeld op te schonen, te mappen of naar een ander formaat om te zetten. Deze transformaties worden uitgevoerd om de juiste kwaliteit en integriteit te kunnen waarborgen. De verschillende acties die uitgevoerd worden zijn te allen tijde auditeerbaar voor compliantie doeleinden of voor diagnose en repareren van data fouten.
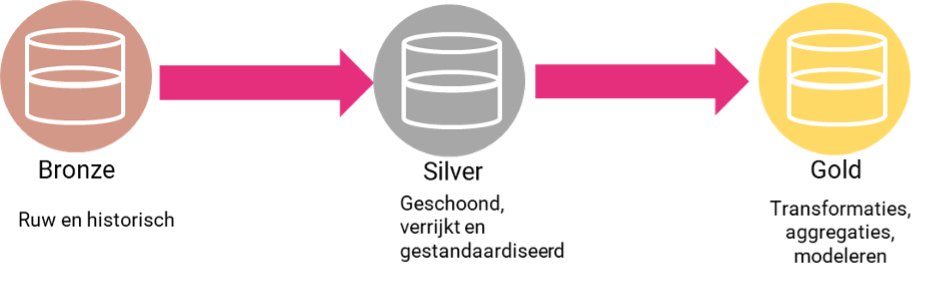
Om dit te kunnen realiseren wordt de data in verschillende etappes getransformeerd en vervolgens verladen. Dit vindt plaatst volgens de “medaillon architectuur” waarbij onderstaande stappen worden genomen.
Laden van data (Load)
Na het doorlopen van een bepaalde transformatie(s) wordt de data gepersisteerd. Dit om hierna weer vervolgstappen mee te kunnen verrichten. Elke laag heeft een ander gebruiksdoel.
- Bronze wordt hierbij gebruikt om de originele staat te bewaren van de brondata. Indien een bepaalde transformatie later aangepast wordt kan deze brondata gebruikt worden om opnieuw de data in te laden.
- Silver met als doel om alle geschoonde data beschikbaar te stellen. Alle data is opgeschoond en eventueel verrijkt door berekeningen ofwel bronnen met elkaar te integreren. Dit wordt gedaan met als doel om alle aggregaties op basis van een en dezelfde bron te doen.
- Gold wordt gebruikt om beschikbaar te stellen voor eindgebruikers. Deze data is getransformeerd voor het specifieke doel waar het voor gebruikt wordt. Dit betekent dus op het juiste aggregatieniveau en datamodel zodat de gebruiker de gegevens direct kan consumeren.
De uitdaging van ETL-dataverwerking
Hoewel ETL essentieel is, is het bouwen en onderhouden van betrouwbare dataverwerkingsprocessen een van de meest uitdagende onderdelen van data engineering geworden. Vooral het bouwen van processen die gegevensbetrouwbaarheid garanderen. Naast dataverwerkingsprocessen is het beheren van de gegevenskwaliteit in steeds complexere architecturen moeilijk. Data van mindere kwaliteit blijft vaak onopgemerkt door een proces heengaan, waardoor de hele data aanlevering als onbetrouwbaar wordt bestempeld. Om de kwaliteit te behouden en betrouwbare inzichten te garanderen, moeten data-engineers code schrijven om kwaliteitscontroles en validatie op elke stap van het proces te implementeren. De Dataverwerkingsinfrastructuur moet worden opgezet, geschaald, opnieuw opgestart, en bijgewerkt worden- wat zich vertaalt in meer tijd en kosten. Om meer te kunnen realiseren, hebben data-engineers tools nodig om ETL te stroomlijnen en te democratiseren, waardoor de ETL-levenscyclus gemakkelijker wordt en data-teams hun eigen gegevenspijplijnen kunnen bouwen en benutten om zo sneller inzichten te krijgen.
Efficiente Dataverwerkingsstrategieen: Autoloader, Delta Live Tables & Workflows
Voor het verwerken van data starten we met het inladen van de data. Vervolgens gaan we in op het beschikbaar maken van tabellen voor rapportages op een efficiënte manier. Globaal heeft Databricks drie methodes om dataverwerking uit te voeren.
Databricks Auto Loader is een functie die het mogelijk maakt om snel gegevens in te laden vanuit Azure Storage Account, AWS S3 of GCP-opslag. Het gebruikt structured Streaming en controle punten om bestanden te verwerken die in de opgegeven directory worden toegevoegd. Op het moment dat bestanden verwerkt zijn dan wordt dit als controlepunt vastgelegd in metadata zodat deze niet nogmaals ingeladen wordt. Met structured streaming is het mogelijk om near real time data in te laden naar de gewenste locatie. Zo kan je deze data bijvoorbeeld doorladen naar delta maar ook aanbieden richting Power BI om zo snel mogelijk inzicht te krijgen in de laatste gebeurtenissen. Auto Loader kan JSON, CSV, XML, PARQUET, AVRO, ORC, TEXT en BINARYFILE-bestandsindelingen inladen. Daarnaast is het mogelijk om Auto Loader in te zetting richting AWS S3, Azure Data Lake Storage Gen2, Google Cloud Storage, Azure Blob Storage, ADLS Gen1 en Databricks File System. Het kan miljoenen bestanden per uur verwerken en schaalt goed om de invoergrootte aan te kunnen. Al met al is Auto Loader de beste functionaliteit om in te zetten vanuit Databricks om je data in te laden.
Wat kenmerkt Auto Loader?
- Schaalbaarheid: Auto Loader kan efficiënt miljarden bestanden ontdekken.
- Efficiënte bestandsdetectietechnieken en schema-evolutiemogelijkheden.
- Autoscaling-infrastructuur voor kostenbesparingen.
- Datakwaliteitscontroles met verwachtingen.
- Automatische schema-evolutiebehandeling.
- Monitoring via metrics in het eventlog.
Auto Loader kan worden geïntegreerd met Delta Live Tables, hiermee kan data van bron tot rapport worden verladen. Met behulp van een paar regels declaratieve Python of SQL kan een data pipeline worden geïmplementeerd.
Wat zijn Delta Live Tables?
Delta live tables is een declaratief ETL framework die je in staat stelt om eenvoudig streaming en batch verwerking op te zetten op een kosten efficiënte manier. Door de declatieve gegevensstromen wordt de data geleid tussen de verschillende tabellen. De tabellen worden automatisch up-to-date gehouden zonder enige zorgen.
Integratie met Databricks workflows
Om vervolgens ervoor te zorgen dat alle dataverwerking geïntegreerd kan worden dien je Databricks workflow te gebruiken. Met deze optie wordt het mogelijk om alle orchestratie van het dataproces af te handelen. Op deze manier wordt het namelijk mogelijk om ook Machine learing en analytisch gegevensstromen te integreren in een proces. Onderstaand een voorbeeld over hoe dit opgezet kan worden.
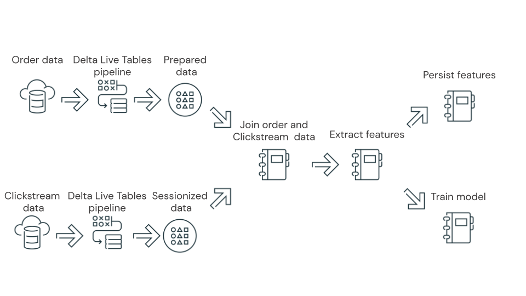
- Voer een Delta Live Tables-proces uit die ruwe stream-gegevens van cloudopslag inlaadt, de gegevens schoonmaakt en voorbereidt, de gegevens persisteert en opslaat in Delta Lake.
- Voer een Delta Live Tables-proces uit die de gegevens van cloudopslag inlaadt, de gegevens schoonmaakt en transformeert voor verwerking en de uiteindelijke gegevensset opslaat in Delta Lake.
- Voeg de gegevens van de stream-gegevens samen om een nieuwe dataset voor analyse.
- Extraheren van kenmerken uit de voorbereide gegevens.
- Voer taken parallel uit om de kenmerken te behouden en een machine learning-model te trainen.
LLM integraties
In de blog Domeinspecifieke AI: De nieuwe horizon in Business Intelligence geschreven door Malcon Halfhuid lees je van alles over LLM. Met databricks is het mogelijk om LLM integraties op te zetten. Gebruik bijvoorbeeld een getrained model zoals “Hugging Face transformers” bibliotheek ofwel OpenAI modellen. Zo is het zelfs mogelijk om met AI functies in SQL data analyst aan te roepen om zo het zojuist toegevoegde LLM model te gebruiken. Zo kan het dataverwerkingsproces gelijk gebruik maken van het model in de gecreëerde databricks workflow. De ontwikkelingen op dit gebied gaan razendsnel. Tijdens de Databricks AI world tour werden we bijgepraat over de nieuwste ontwikkelingen die eraan zitten te komen. Ook nieuwsgierig geworden of heb je nog vragen over deze blog? Neem dan even contact op via deze link en dan praten we je helemaal bij!